ヌーラボ技術の裏側
ヌーラボのプロダクトを支える技術の裏側を紹介します。
目次
ヌーラボは、「“このチームで一緒に仕事できてよかった”を世界中に生み出していく」をブランドメッセージとしてサービスを展開しています。
私たちのサービスは、世界中のチームの大切なコラボレーションの場として日々活用されています。その舞台裏では、ヌーラボが長年培ってきた技術と知見が、サービスの安定性と進化を支え続けています。そんな技術の裏側にある物語を、少しだけ紹介します。
BacklogのGitホスティングを支える技術
Backlogが提供するGitホスティングにおいて、可用性・信頼性を保つためにどのように冗長化と負荷分散を実現しているのか。ここでは、その仕組みやアーキテクチャの概要を解説します。
Gitリポジトリの特性とストレージ
ベアリポジトリ
Gitリポジトリは、ベアリポジトリと呼ばれる、ワークツリーを持たない.gitディレクトリの構成だけが存在する形式で保存されています。Gitリポジトリを単位にした、独立したオブジェクトデータベースのようなイメージです。
Amazon EBS
Gitリポジトリは、安定したパフォーマンスが得られるブロックストレージであるAmazon EBSに保持されています。複数ホストから共有はできないため、レプリケーションにより冗長化を実現する必要があります。
全体アーキテクチャの概要
ステートレスなフロントエンド
Web・API・Gitクライアント(HTTPS/SSH)のリクエストを受け、認証/認可を行う部分です。ストレージを持たないためコンテナで運用しやすく、スケールアウトしやすい部分です。
ステートフルなバックエンド
Gitリポジトリを実際に保持するコンポーネントであるGit RPCは、EBSをマウントしたEC2上で稼働しています。Primary-Replica構成で冗長化しており、Write系はすべてPrimary、Read系はPrimaryかReplicaで処理します。gRPCを使って用途に合わせた複数のRPCを提供しています。
中継役のgit-proxy
フロントエンドからのすべてのRPCを受け取り、バックエンドへ転送(リバースプロキシ)。レプリケーションのためのログ管理やSQS送信など、中核的な制御を担います。
gRPCでつなぐマイクロサービス
Git特有の通信の特性にあわせて、gRPCが提供する複数の通信方式を使い分けています。
- 大容量データ取得(git clone/pull/fetch):Server Streaming RPC
- 大容量データ送信(git push):Client Streaming RPC
- その他の小さなデータ:Unary RPC
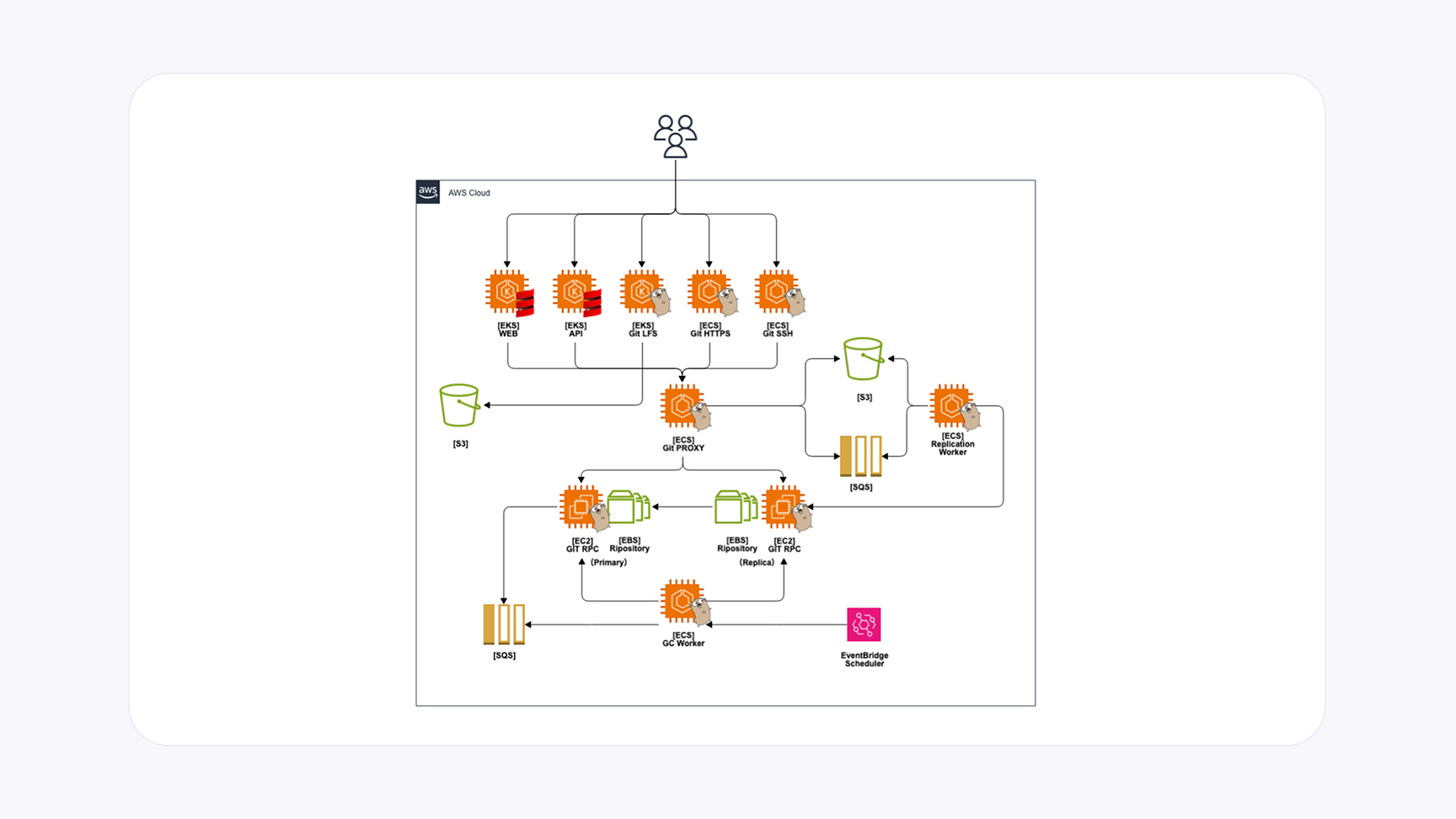
非同期レプリケーションを用いた冗長化の仕組み
レプリケーションログ(S3)
git-proxyが書き込み処理をバックエンドに中継する前に、レプリケーションに必要な情報をS3に保存します。S3は「Strong Consistency」をサポートしているため、常に最新の状態を取得可能です。
Amazon SQS(FIFO)による順序制御
書き込みが成功すると、レプリケーションを通知するためにAmazon SQSへメッセージを送信します。メッセージの順序性が重要となる複数イベント(リポジトリ作成→書き込み→リネーム→削除など)を保証するため、FIFOキューを活用しています。グループIDを同一にすることで同じリポジトリ関連の処理順序を担保しています。
レプリケーションワーカー
実際にレプリケーションログを受け取るワーカーが、SQSをポーリングし、取得したメッセージに含まれるログをもとに、レプリケーション種別に応じてGit RPCが提供するレプリケーション用のRPCを実行します。成功時にS3とSQSのメッセージを削除、失敗時はリトライします。
冪等なレプリケーションRPC
何度実行しても差分のみ処理する git fetch を利用することで、冪等性を担保しています。
さらなる信頼性と拡張性のために
BacklogのGitホスティングでは、EBS上のGitリポジトリをPrimary/Replica構成で保持し、非同期レプリケーションを用いて高い可用性とパフォーマンスを両立しています。フロントとバックを明確に分割し、gRPCやSQS、S3などを組み合わせて柔軟な冗長化・負荷分散を実現している点が特徴です。将来的には「3フェーズコミット」などの分散アルゴリズムを活用し、複数ノードへのリアルタイムな書き込みを実現する同期レプリケーションなどの技術的拡張も視野に入れています。
こうした取り組みを通じて、変化するワークロードにも柔軟に対応できる仕組みを目指しています。
なぜBacklogはCRDTを選んだのか?
共同編集技術の裏側
Backlogのドキュメント機能では、複数人が同時に文書を編集できる「共同編集」を実現しています。この開発にあたり、私たちはCRDT(Conflict-free Replicated Data Type)を採用しましたが、最初からこの選択肢が見えていたわけではありません。ここでは、開発現場での試行錯誤と技術的な工夫を紹介します。
なぜCRDTを採用したのか?
共同編集を実現する技術には、OT(Operational Transformation)とCRDT(Conflict-free Replicated Data Types)の2つの選択肢がありました。当初はOT対応のQuillエディタを検討しましたが、日本語IMEの不具合が壁となり、日本語IMEに強いエディタを探した結果、ProseMirrorを採用することになりました。これにより、yjsライブラリを活用して共同編集の基盤が構築できました。
CRDTがもたらした技術的メリット
- サーバー負荷の軽減
OTではサーバーで操作の整合性を計算する必要がありますが、CRDTでは操作がクライアント側で処理されるため、サーバーの負担が大幅に軽減されました。 - ネットワーク障害への対応
CRDTはオフライン時でも操作をローカルに保存し、再接続後に自動で同期を回復します。これにより、ネットワーク障害を気にせず共同編集を続けられます。 - リッチな内容への柔軟な対応
課題埋め込みやメンションやコールアウトなどのリッチな編集要素を簡単に組み込むことができ、Backlog独自の機能強化に役立っています。
共同編集技術のこれから
CRDTは、サーバー負荷の軽減や耐障害性、リッチコンテンツ対応といった大きなメリットをもたらしました。一方、データ容量が大きくなるという課題がありますが、圧縮技術を活用して対応しています。今後も、共同編集をより高機能でスムーズなものに進化させるため、新たな技術への挑戦を続けていきます。
Cacooチームのレビューを変えた
検証環境の自動構築
Cacooでは、新しいコードのレビューを効率化するため、プルリクエストを起点に検証環境を自動構築する仕組みを導入しました。この仕組みにより、エンジニアだけでなくデザイナーやマネージャーも簡単に動作確認ができるようになり、チーム全体の開発プロセスが大きく改善されました。
今回は、この仕組みを構築するに至った背景や課題、技術的な工夫を紹介します。
Cacooの検証環境で起こっていた課題
以前のCacooチームでは、ひとつの検証環境を複数のプロジェクトが共有していました。その結果、以下のような問題が発生していました。
- 複数のブランチが検証環境を奪い合い、変更内容が上書きされる
- エンジニア以外のメンバーが動作確認をしたいタイミングで環境が使えない
- バージョンの衝突や混乱が頻発し、リーダーが調整に追われる
こうした課題を解決するため、私たちは「プルリクエストごとに独立した検証環境を自動で作成する」仕組みを開発しました。
自動検証環境の仕組みと技術的工夫
自動検証環境の仕組み
この仕組みの核心は、プルリクエストが作成された際に専用の検証環境をKubernetes上で自動構築することです。以下がその流れです。
- プルリクエストの作成
プルリクが作成されると、CIツール(Jenkins)が動作し、Kubernetesに新しいPodを作成する命令を送ります。 - 独立した検証環境の構築
各Podはプルリクエストに対応したフロントエンドコードを含み、アクセス用の専用URLが発行されます。このURLを使用することで、検証環境が簡単に共有可能です。 - 自動削除の実装
KubernetesのJobを利用し、一定時間が経過したPodは自動的に削除され、無駄なリソース消費を防ぎます。
Kubernetesの活用
KubernetesのDNSやPod管理機能を応用し、プルリクエストごとの動的な環境構築を実現しました。また、Service Accountを利用してCI環境から安全に操作できるようにしています。
導入後にレビュー効率が大きく向上
この仕組みのおかげで、検証環境の準備が自動化され、誰でも簡単に動作確認ができるようになりました。各プルリクエストが独立した環境を持つため、バージョン衝突の心配もなく、レビューの依頼もURLを共有するだけでスムーズに進められます。
Cacooのチームメンバーからも以下のような声が寄せられました。これらの声はエンジニアにとっても大きな励みです。
今後は、この仕組みをさらに進化させ、バックエンドや他の領域にも展開も進めていきます。
「パスキー」導入で
ログインをさらに簡単・安全に
ヌーラボでは、ユーザーがより安全かつ快適にサービスを利用できるように、ヌーラボサービスのログイン方法の革新に取り組んでいます。その一環として、パスワードを使わずにログインできる生体認証「パスキー」を導入しました。
ここでは、パスキーを採用するに至った背景や、その技術的な特徴について深掘りしてみます。
なぜパスキーを導入したのか?
従来のパスワードは、多くのセキュリティリスクを抱えていました。主な理由にリスト攻撃やフィッシング被害、ユーザーの負担となる管理の複雑さなどが挙げられます。これらの課題を解決するために、「FIDO」という国際規格の認証技術に基づくパスキーを採用しました。
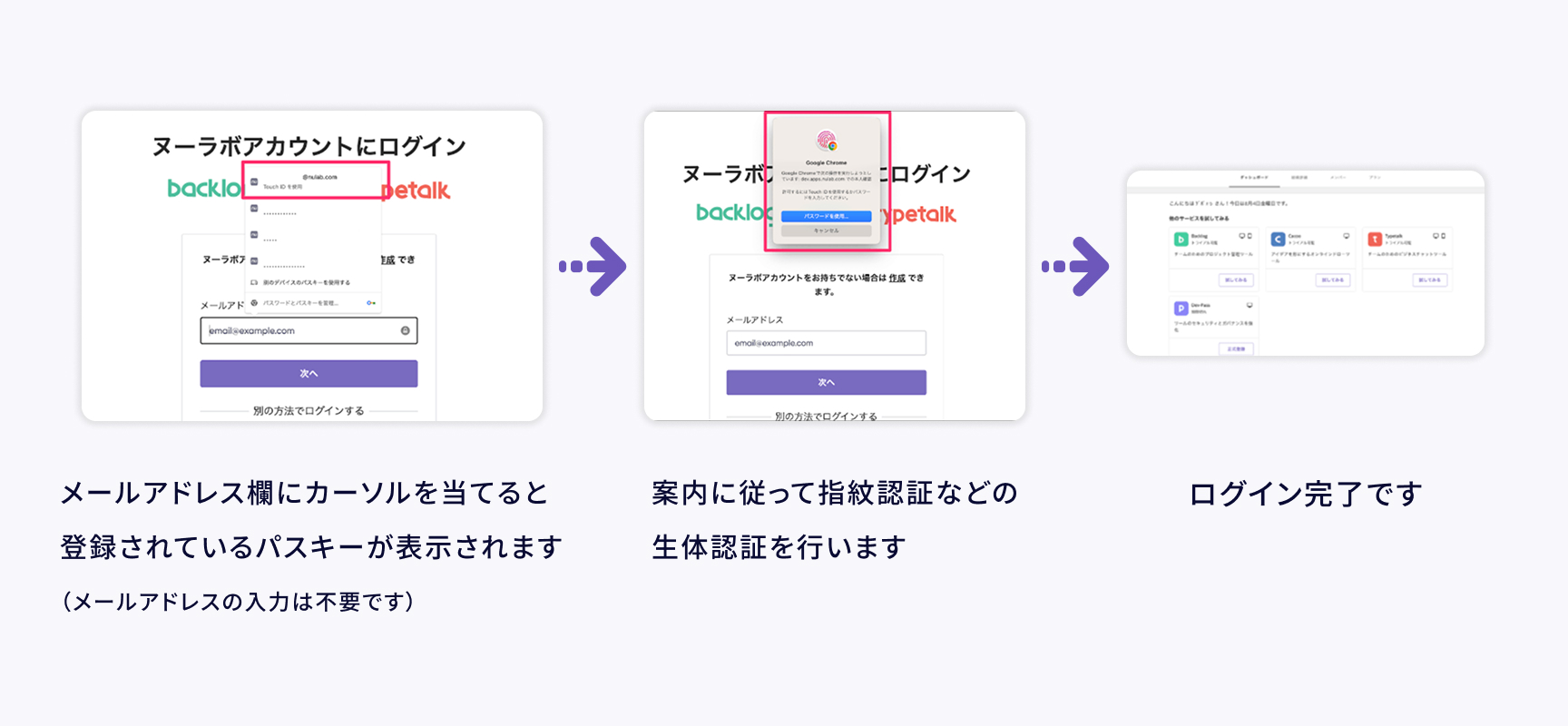
安全性を向上させるパスキーの仕組み
パスキーは、セキュリティと利便性を両立できる、パスワードに代わる認証手段です。この仕組みによって、パスキーはネットワーク上でのパスワード流出を根本から防ぎ、安全な認証を可能にしています。
パスワードレス
パスキーでログインする場合はパスワードの入力は不要です。従って、ネットワークからパスワードが盗まれたり、リスト攻撃されたりするなどのリスクはありません。
多要素認証
パスキーはローカル端末に秘密鍵を、サーバー側に公開鍵を保存する仕組みで動作します。秘密鍵にアクセスする際には、指紋や顔認証といった生体認証を使用します。この方式により、「本人確認」と「デバイス所持」の多要素認証を実現し、従来のパスワード認証と比べて、より高いセキュリティを提供できます。
生体情報や秘密鍵の安全管理
生体情報はローカル端末内でのみ使用され、サーバーに送信されることはありません。また、秘密鍵はAppleやGoogle、Microsoftなどのパスキープロバイダによって安全に管理されます。
フィッシング攻撃に強い設計
パスキーは特定のドメイン(例:nulab.com)と紐づけられているため、偽サイトでは機能しません。この仕組みにより、フィッシング攻撃のリスクを無くしています。
日々の小さな体験をより良くしていく
パスキーは、パスワードの煩わしさを解消し、ログインをもっと簡単で安全なものにするための仕組みです。私たちが目指すのは、ユーザーが余計なストレスを感じず、安心してサービスを利用できる環境です。これからも、日々の体験を少しずつ良くしていく技術に挑戦していきます。


